We all know data is important for growing a business, yet we rarely see examples of data initiatives delivering value for small or mid-sized businesses. Why is that? Too often, organizations focus on acquiring tools or collecting massive amounts of data without a clear plan for how it will drive meaningful outcomes. This leads to wasted resources, fragmented systems, and frustration when the insights don’t materialize.
The truth is, a successful data strategy isn’t about fancy dashboards or advanced algorithms—it’s about aligning data initiatives with your business goals and ensuring they produce actionable insights. In this article, we’ll walk you through how to build a data strategy that delivers tangible value, even if you’re working with a smaller team or limited resources.
There are two options to guide you through this process. You can follow the step-by-step breakdown provided in this article, or you can dive deeper with our Data Strategy Guide, which includes a workbook and a 2-part video series. The guide combines videos, slides, and actionable templates to give you everything you need to craft and implement your strategy. Whichever path you choose, you’ll have the tools to make data work for your business. Download the guide now to get started!
Table of contents
Step 1: Getting the stakeholders involved
Why engage stakeholders?
- Shared vision and buy-in: Ensuring that all stakeholders understand and share the vision of a data-driven organization is key. This collective understanding fosters a sense of ownership and commitment to the change.
- Diverse perspectives: Different stakeholders bring unique insights and perspectives that can help identify potential challenges and opportunities from various angles.
- Resource allocation: Stakeholder support is often crucial for securing the necessary resources – budget, personnel, or technology – to build and sustain data initiatives.
Who leads the data strategy engagements?
The best organizations create a cross-functional team typically led by someone in a Data/Analytics role or a leader within the IT organization. Sometimes, this team is led by a leader within a business unit or a central business team. This individual serves as the “point person” responsible for driving success.
Pro tip: It’s important to ensure the point person has a clear line of sight and understanding of your current data platform architecture. They should be comfortable making technology decisions for the organization and, ideally not develop the data strategy in a vacuum.
How to engage stakeholders?
Identifying key stakeholders
Start by identifying who needs to be involved. This typically includes senior management, department heads, IT personnel, and key team members whom the shift toward data-driven practices will directly impact.
List the stakeholders in the “Stakeholders list” sheet from The Data Strategy Workbook.
Understand the motivations and concerns of each stakeholder. Customize your communication to address their interests and how a data-driven approach can benefit their domain.
Use concrete examples and case studies to showcase the benefits of being data-driven. Highlight how similar organizations have achieved success by adopting data-centric practices.
Implement small-scale pilot projects to demonstrate the practical benefits of data-driven decisions. Choose projects with visible and measurable outcomes to build confidence and showcase quick wins. Chapter 4 will cover how to develop value-packed short development sprints.
Involve stakeholders in these pilot projects, giving them a firsthand experience of the process and benefits.
Pro tip: Marketing tends to be the perfect place to start. With standardized data sources and results significantly tied to data, it makes for an ideal starting point to demonstrate value.
Step 2: Discovery
1. Current & desired state
2. Business impact assessment
In The Data Strategy Workbook, access the Business impact assessment questions by clicking the “ + ” symbol at the top of column K. Answer the business impact questions. The more yeses you have, the higher the impact answering that question will have.
Pro tip: You may consider a question high impact even if it has few yeses. If that’s the case, set the business impact value to what you think is fair, communicate the reason to other stakeholders, and move on.
3. Data profiling
- Good: Historical and new data quality is good enough for analysis.
- Good moving forward: The data quality of the new data is good enough to be used for analysis. Historical data can’t or won’t be fixed. We will simply ignore historical data.
- Could be good: The data quality of the new data is good enough to be used for analysis. Historical data can and should be fixed.
- Bad: The data quality of historical and new data is NOT good enough for analysis.
Step 3: Data platform architecture

Choosing your data platform technologies
- Scalable
- Flexible & agile
- Performant & efficient
- Reliable
- Secure
- Cost-effective
- Easy to integrate with your existing IT ecosystem
- Allows easy data democratization
- Well documented
Data transformation before analysis is not just a procedural step but a strategic necessity. Through these processes, data transformation will empower your organization to unlock the true potential of its data assets.
What is a data platform?
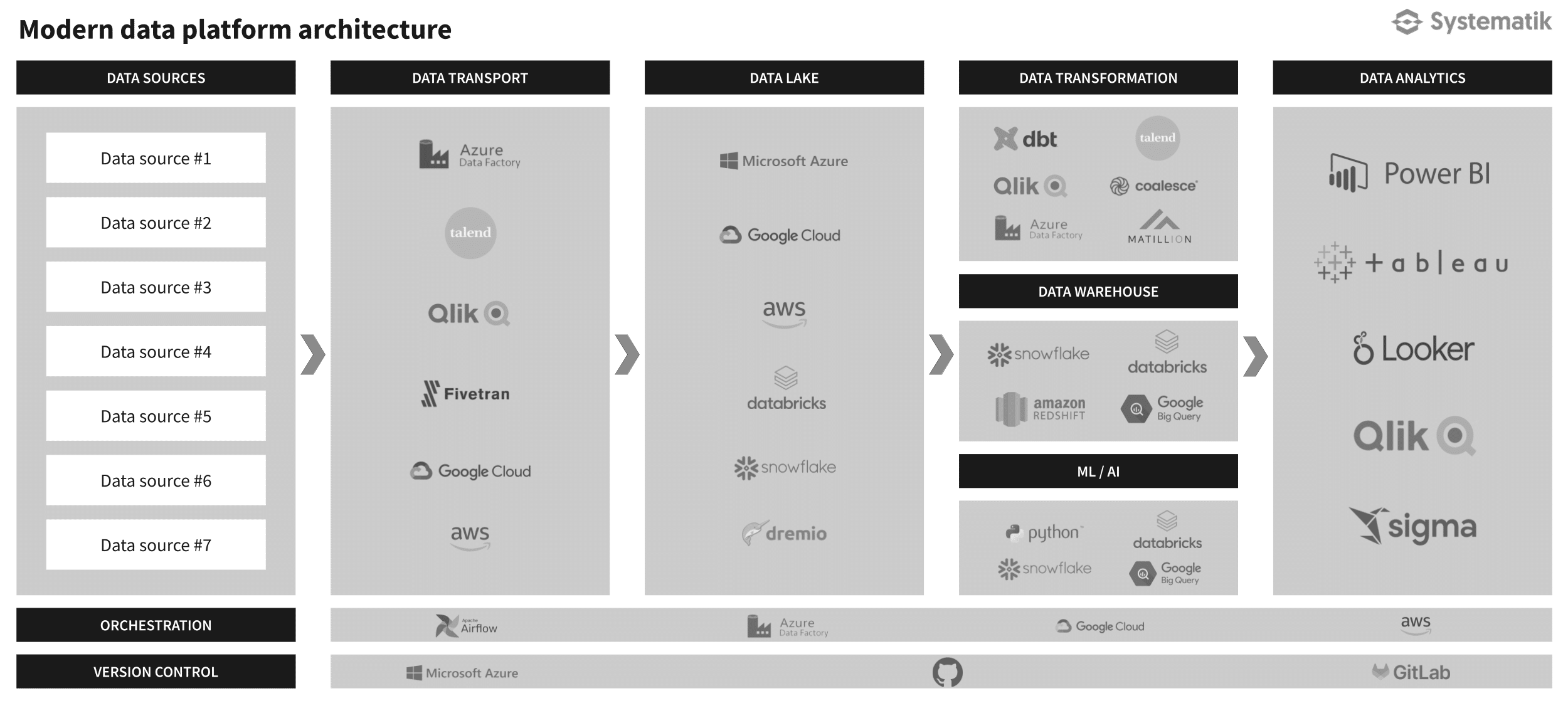
Pricing
For a more comprehensive assessment, complete the data platform technologies architecture checklist from the “checklist” sheet of The Data Strategy Workbook. Then use the “DPT comparison matrix” to easily compare the technologies you are considering.
The all-in-one solution trap
- It has data visualization capabilities
- It offers many connectors to data sources across many industries (marketing, operations, finances, data warehouses, ERP, CRM, etc.)
- It offers a robust set of data transformation features
Limited Data Ownership: Without a dedicated data warehouse, your data is stored externally, leaving you vulnerable if the vendor ends support or shuts down, potentially causing irretrievable data loss.
Pro tip: As a general rule, wherever possible, data transformation logic should not live in your BI tool.
Drafting your data platform architecture diagram
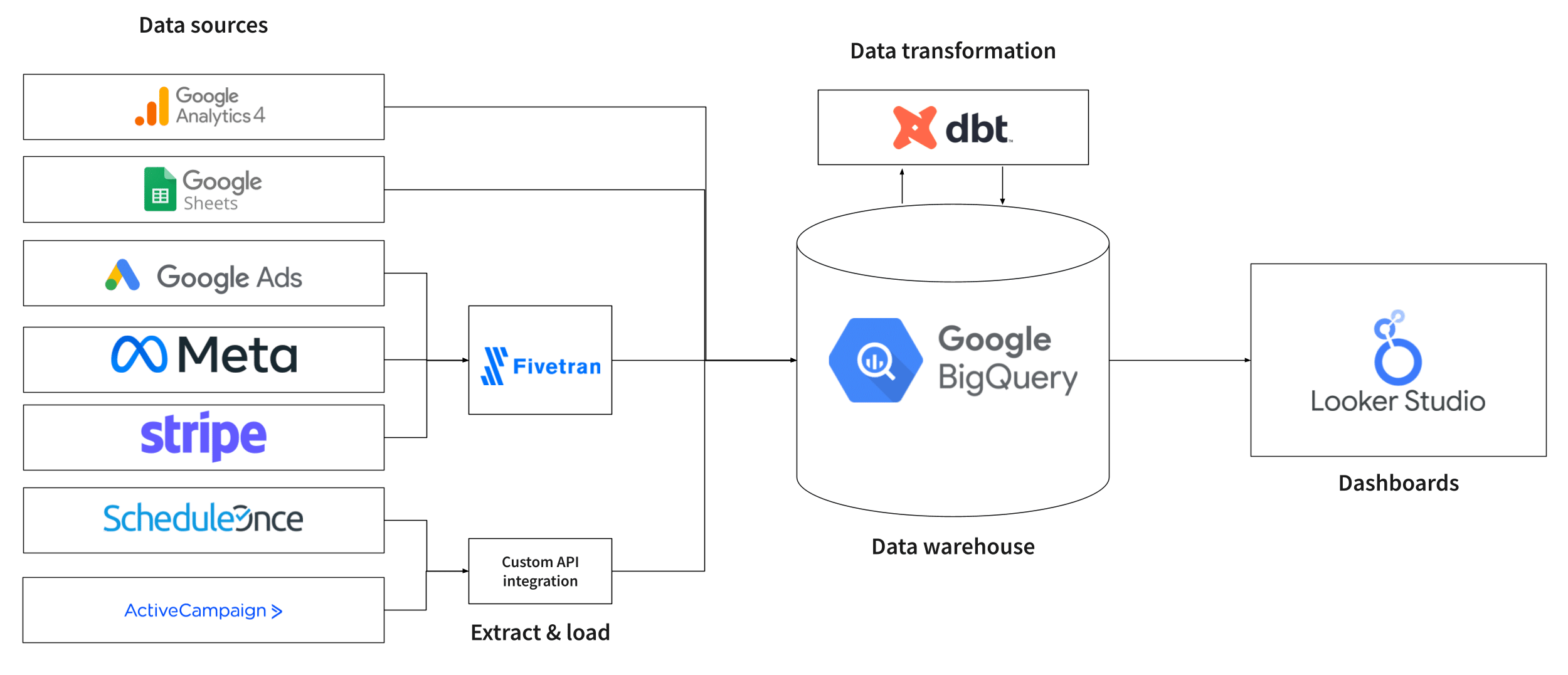
Why data needs to be transformed
To learn more on this subject, I encourage you to read our article “Why data needs to be transformed“.
Step 4: Data governance
Definition & planning
Pro tip: Data governance should be an iterative process. As data platforms mature, the impact of not having specific components of a data governance program becomes increasingly important. On the other hand, over-engineering a data governance program can slow down progress and limit business value. The key is balance.
Maintenance
Data pipelines collect data from various sources, combine them, apply several transformations, and form them into a single source of truth. A good robust pipeline will consistently deliver error-free data, but only as long as the sources it is designed for stay the same, which is rarely the case. Most pipelines are built assuming fixed schemas for the sources, which include column names, data types, or the number of columns. The slightest change in these data standards can break the pipeline, disrupting the entire process.
To learn more, read our article on “Why data pipelines need to be maintained“.
Next, we’ll look at the planning and implementation of a data strategy.
Pro tip: Robust documentation, quality checks, and alerts not only boost your data’s value but also cut maintenance costs significantly. Keep your data governance tight to keep your data clean and your costs down.
Step 5: Implementation & timeline
This step depends on how you plan projects at your organization, so we won’t spend too much time discussing this. Without going into the details of sprint planning, a good plan should have the following:
Effort required
To gain momentum and quickly prove the value of your data initiative, we recommend starting with the questions that fall in the “Quick wins” category.
Sprint planning
Pro tip: It’s crucial to resist overburdening a sprint with too many tasks or objectives. Balance your ambitions with the practical realities of your workflow, ensuring that each sprint is structured to deliver high-quality, well-documented outputs that stand the test of time. This might mean being more selective about what you commit to in each sprint, but it ensures you maintain the high standards your work requires and your stakeholders expect.
Conclusion
We hope this guide and our Data Strategy Workbook have been helpful resources on your organization’s data-driven journey. The core concepts and recommended practices outlined are relevant for any organization, regardless of their size, industry, or current level of data and analytics maturity.
At Systematik, we understand the critical role this work plays in achieving your goals. We stand ready to support you, leveraging years of experience and expertise gained from working with clients at all stages of development. We offer a comprehensive toolkit including tools, processes, reference architectures, and a team dedicated to empowering you to unlock the full potential of data and analytics within your organization.
If you need help with your data strategy, we’re here to assist. Book a free consultation with us today, and let’s start building a strategy tailored to your business needs.