To answer this question, we need to understand how raw data is structured and how business questions are typically structured. Let’s dive in and see why transforming data is more than an unnecessary hurdle – it’s your key to smarter, more insightful business decisions.
Table of contents
Reason #1 - Combining multiple data sources
Imagine that you are operating an e-commerce business using Shopify.
A typical business question would be something like this:
What was our revenue by product, by state, in November 2023?
In a perfect business intelligence world, our Shopify data would be structured like this:
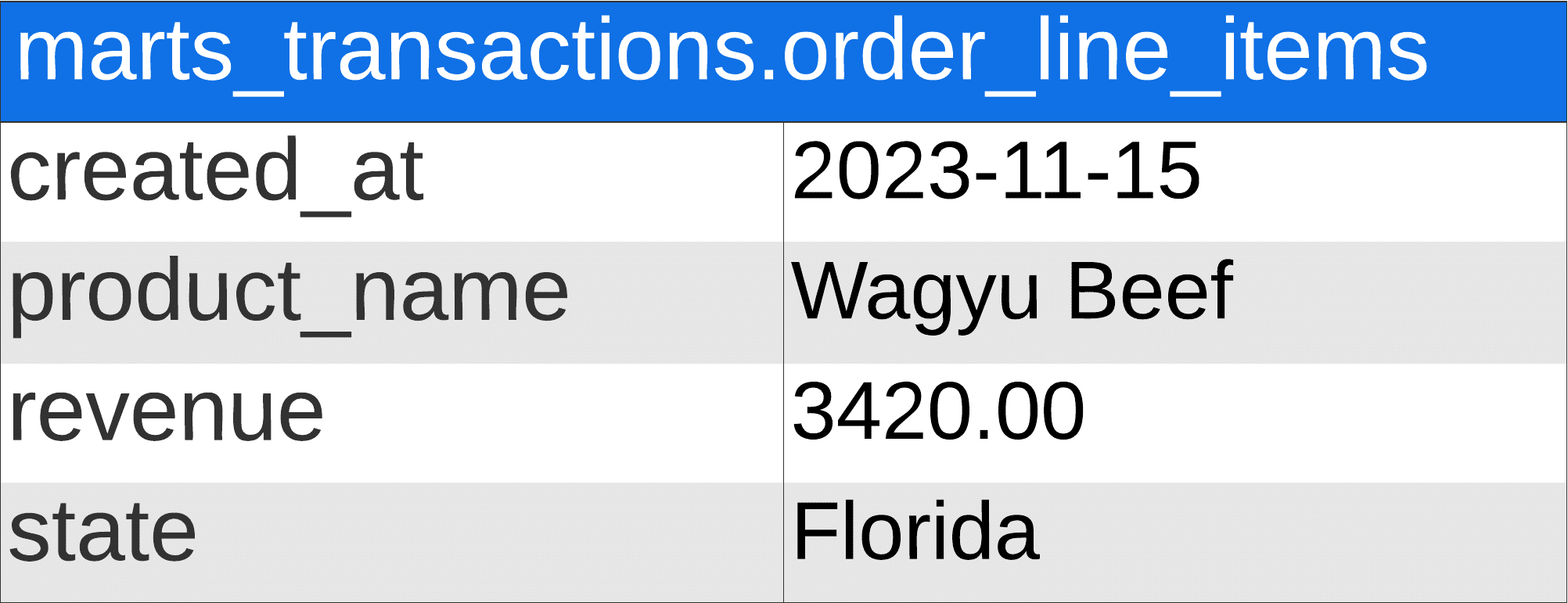
Data would be aggregated, we would have date, revenue, and state columns, and life would be good. Unfortunately, data from software is organized very differently than what we need for business intelligence.
Here’s what Shopify data looks like:
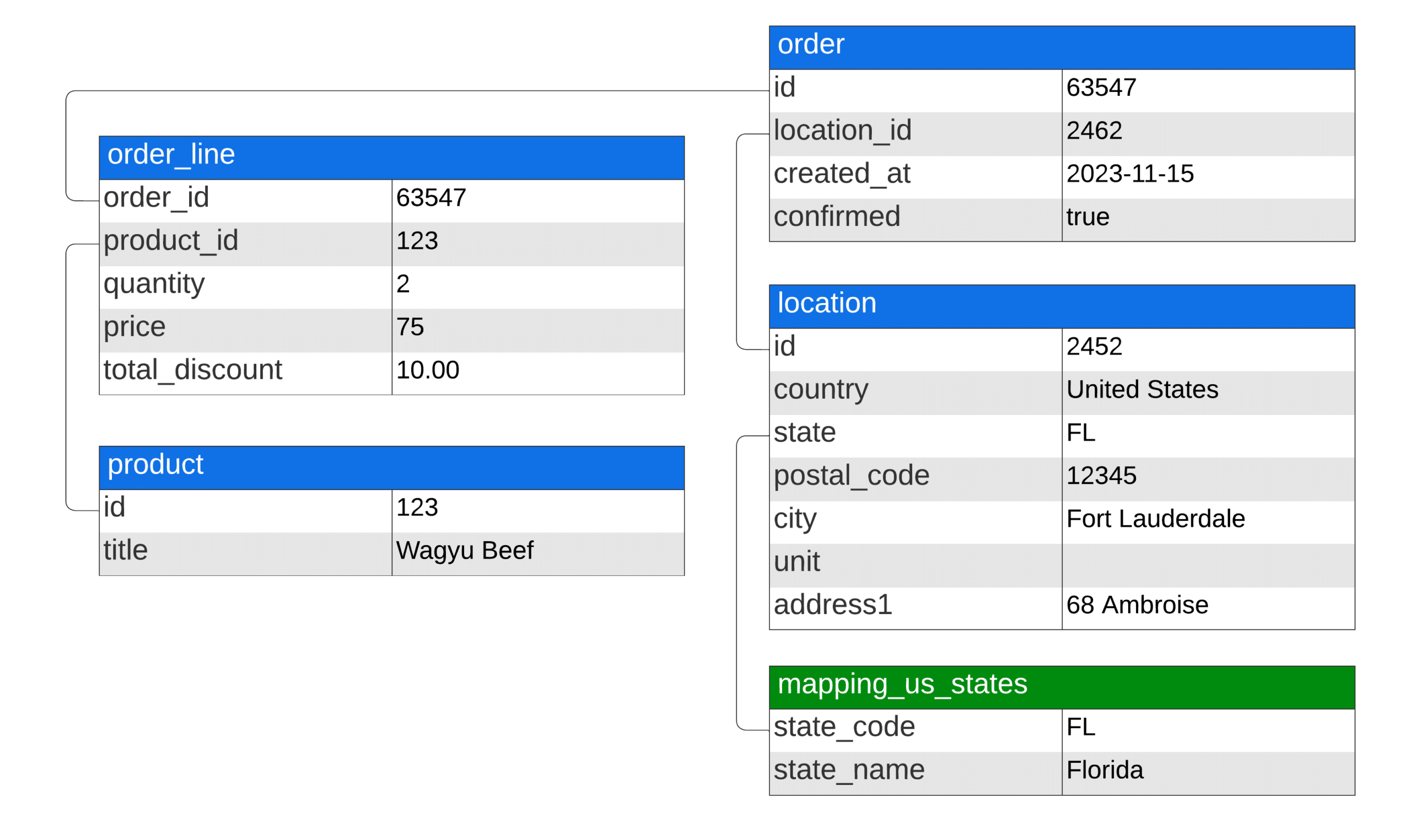
Keep in mind that this is an overly simplified example. Once we start adding different data sources, complex business logic, and complex join, it becomes even more obvious why raw data shouldn’t be used for business intelligence.
Reason #2 - Data enrichment
Here are two examples of data enrichment:
Customer Segmentation in Retail: A retail company has basic customer data (e.g., age, gender, purchase history). The company can create detailed customer segments by enriching this data with additional information such as income levels, geographic location, and online browsing behavior (from cookies and web analytics). These segments allow for targeted marketing campaigns, personalized product recommendations, and improved customer service, ultimately enhancing customer satisfaction and loyalty.
By integrating additional information, refining existing data, and generating new insights, you’ll be able to unlock deeper, more actionable intelligence from your datasets.
Reason #3 - Improving data quality
High-quality data is the foundation of a data-driven approach to business, and data transformation processes are essential for solidifying this foundation.
Reason #4 - Performance & cost efficiency
Transforming data to improve query performance and cost efficiency involves restructuring or processing data to make it more accessible and quicker to query while also managing the resources used more efficiently. This can include several specific transformation actions, such as:
By incorporating these transformation strategies, the data becomes more aligned with the requirements of the querying and analytical processes, leading to faster query times and potentially lower costs, especially in pay-per-query or resource-intensive environments. This consideration is particularly relevant in cloud-based and big data platforms, where the volume of data and the complexity of queries can significantly impact costs and performance.
Reason #5 - Ensuring confidentiality & regulatory compliance
Many industries are subject to regulations (like GDPR in the EU, HIPAA in the US for healthcare data, or CCPA in California) that mandate the protection of personal data. Transforming data to comply with these regulations is not just best practice; it’s a legal requirement.
Reason #6 - Tracking changes over time
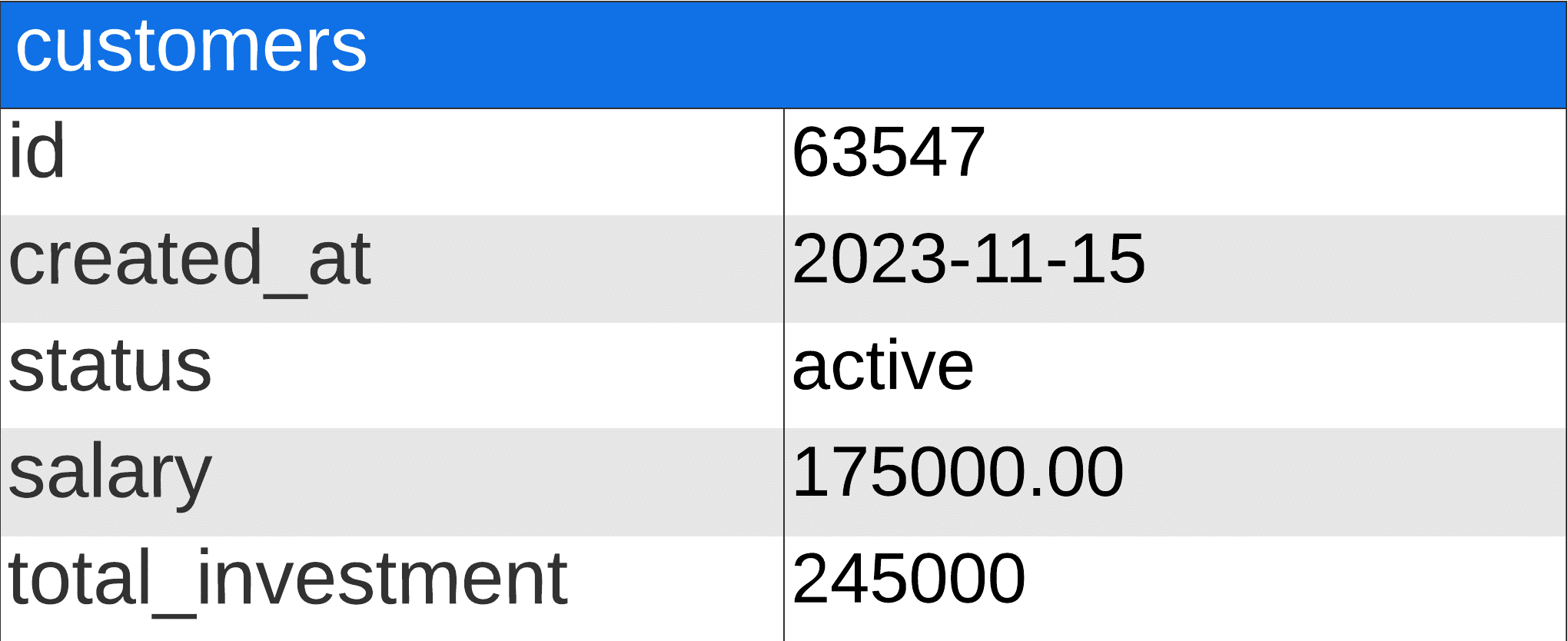
Salary, total_investment, and status are the most recent and only available records. What if you’d like to know the average salary of your customers when they made their first investment, and what was the amount of that first investment? You couldn’t.
Another example would be an e-commerce company that wants to track gross margins over time. To do so, they use the following formula:
({SKU cost + Shipping cost} / {Revenue}) * 100
By storing snapshots when changes occur, you unlock new analytics capabilities
Reason #7 - Optimizing for specific tools
Here are some examples where that is true:
In each of these examples, the transformation of data to suit the specific requirements of tools and platforms is fundamental to unlocking the full potential of data analysis and processing capabilities
Conclusion
Book a free strategy session to discover how we can help you transform your business by transforming your data.